Configuration drift- why it's bad and how to solve it with GitOps and ArgoCD



Configuration drift refers to the disparity between configurations as coded in repositories like Git and what’s actively deployed. Despite embracing continuous integration and continuous deployment (CI/CD) methodologies, modern software organizations still grapple with this disparity, which not only complicates deployments but can also jeopardize the stability of production environments.
For example, imagine a scenario where a Continuous Deployment (CD) pipeline deploys an application to a Kubernetes cluster, with all configurations codified in a Git repository, as shown in the following diagram:
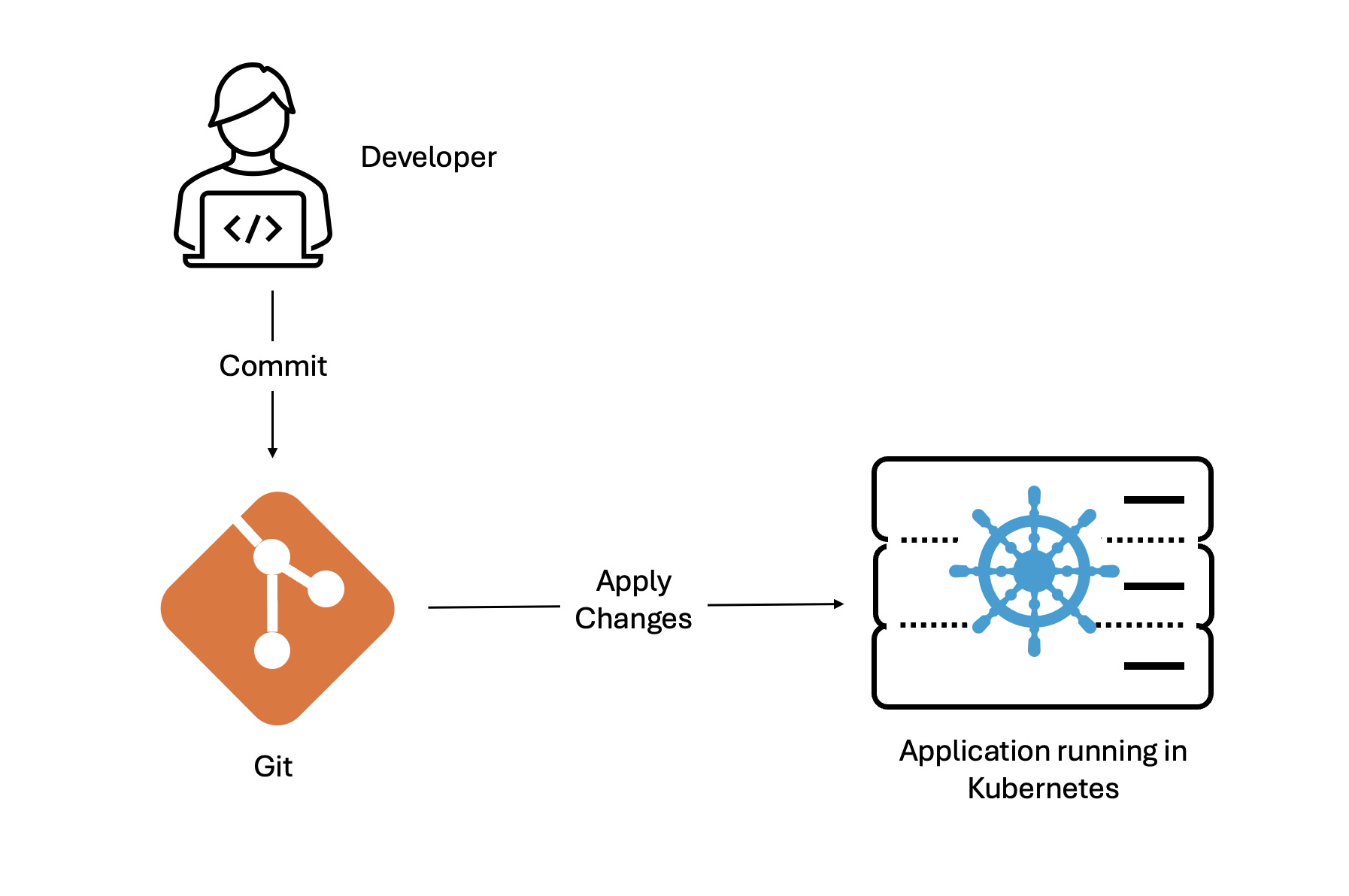
Everything operates seamlessly. In the next image, developers make changes and updates to the application. They commit these changes to the Git repository and push to the deployed application, updating our app in production. All good so far.
However, a team member identifies a performance issue and, aiming for a quick fix, uses a kubectl command to directly tweak the resource allocations for a specific deployment. In this case, they’ve gone straight to the production deployment!
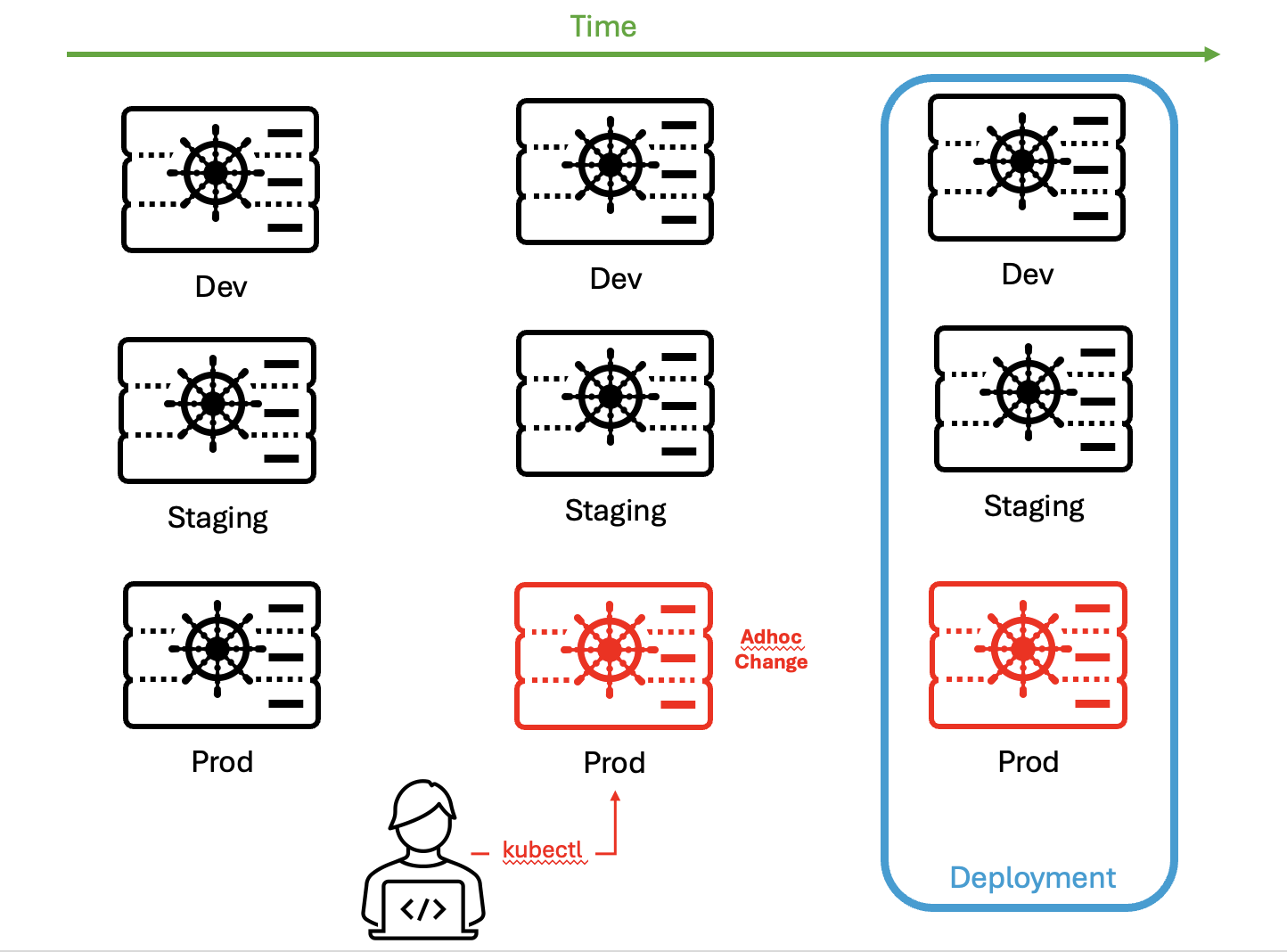
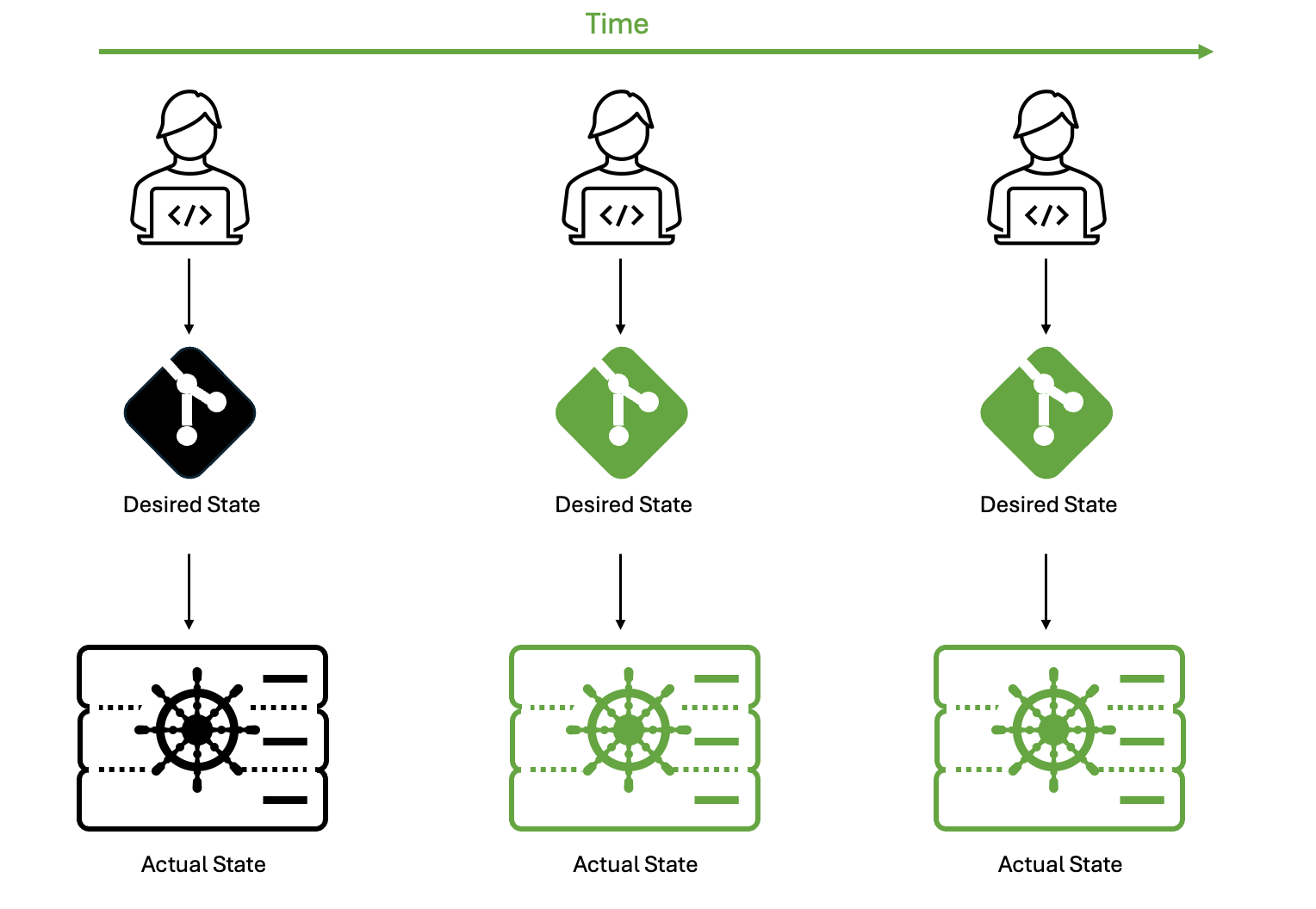
Although this fix might resolve the immediate problem, the cluster’s state now diverges from what’s documented in Git.

As many organizations use the same Git repo to configure dev, staging, and prod Kubernetes clusters, changes to only one cluster (in this case, prod) cause drift between the clusters.
The next time that a deployment occurs, unexpected behaviors might arise because the CD pipeline assumes that the cluster matches the Git state. Additionally, other team members might remain unaware of this change, leading to potential troubleshooting challenges and operational inefficiencies down the line.
Why is configuration drift bad?
The consequences of configuration drift can vary in severity from mildly inconvenient to extremely serious and business threatening. However, no matter the severity, configuration drift results in liabilities and negative impacts on your app, team, and business.
At the very least, configuration drift can cause:
-
Extra work for the team
-
Lost productivity
-
Reduced efficiency
-
Downtime of nonessential services
-
Difficult audits
At worst, drifted configurations can be responsible for:
-
Unpatched security vulnerabilities or absent security protocols that lead to cyberattacks and breaches
-
Compliance violations resulting in fines and reputational damage
-
Downtime of essential services
-
Whole app failure
-
Data loss from misconfigured backup and storage settings
-
Unreliable behavior in production due to inconsistent deployment environments
The difficulty with configuration drift is that the longer you leave these problems and the larger the differences in configuration, the worse these problems become, rapidly! If you allow many individual misconfigurations to pile up over time without addressing them, they will quickly compound together. The result is configuration drift that could have been an easy fix becoming a major problem.
This is why it is critical that you mitigate and solve any potential configuration drift in your own applications.
What causes configuration drift?
Typically, the most common causes of configuration drift are ad hoc manual changes by developers or admins, like the scenario we explored at the start of this post. However, other potential causes can include:
-
Software patches that alter system configurations
-
Software or hardware updates that conflict with existing configurations
-
Poor communication: for example, if one team does not inform other teams about a setting modification.
-
Poor documentation: if config changes are not effectively documented, team members might not know how to properly configure systems.
-
Human error, such as typos and other incorrect attributes.
As you can see, there are many reasons why configuration drift happens. But regardless of how it happens, configuration drift occurs when code changes get through without being monitored or approved.
What can make this even worse is the potential for developers to create even more configuration drift while trying to solve issues that are caused by configuration drift. As they try to fix these problems, more code changes get pushed without proper review, monitoring, tracking, or reporting, which leads to even further inconsistency between the desired configurations and actual state. This vicious cycle can continue to snowball, creating more drift and more serious problems!
So, how can we mitigate configuration drift, and what tools and strategies can we use?
How do we solve configuration drift?
To solve configuration drift, we must reconcile any potential configuration differences and ensure consistency across our deployments.
To do this, we can use GitOps, using Git as the single source of truth for declarative infrastructure and applications. GitOps is a framework that streamlines and optimizes how operations and infrastructure are handled in the modern cloud-native landscape. GitOps revolves around four core principles:
- Declarative configuration
-
In GitOps, all resources and infrastructure are defined declaratively. This means the entire system – from infrastructure, networking, and even application deployments – is described in a manner where you state "what" you want, not "how" to achieve it. These declarations are usually made through config files or manifests.
- Versioned and immutable source of truth
-
Every declared configuration is stored in a version-controlled Git repository. This repository acts as the immutable source of truth for both infrastructure and application. Any change, be it a minor configuration tweak or a major system overhaul, is recorded as a commit, ensuring full traceability and history.
- Automated delivery
-
Once a change is committed to the Git repository, automated processes handle the deployment. This ensures that the live system is always in sync with the repository’s declared state. If any difference arises – whether due to manual interventions, system failures, or other reasons – the GitOps process can either flag it or work to reconcile the live state to match the repository.
- Continuously reconciled
-
Continuous feedback is integral to GitOps. Monitoring and alerting tools keep a watchful eye on the live environment, comparing its state to the repository. If discrepancies are detected, these tools alert operations teams or even trigger auto-correction processes, making sure the desired state, as defined in Git, is consistently maintained.
GitOps is more than just a set of tools or practices. It’s a cultural shift in how infrastructure and applications are managed, drawing from proven development practices and extending them to operations. By tightly integrating Git at the center of the operational framework, GitOps ensures reliability, transparency, and efficiency in modern deployment pipelines. In essence, GitOps ensures that the actual state of a cluster is always equal to the desired state in Git.
Now that you understand the principles of GitOps, you can see that achieving its full potential requires tools designed with these principles in mind. Let’s explore what tools we can use.
How does ArgoCD help enable GitOps?
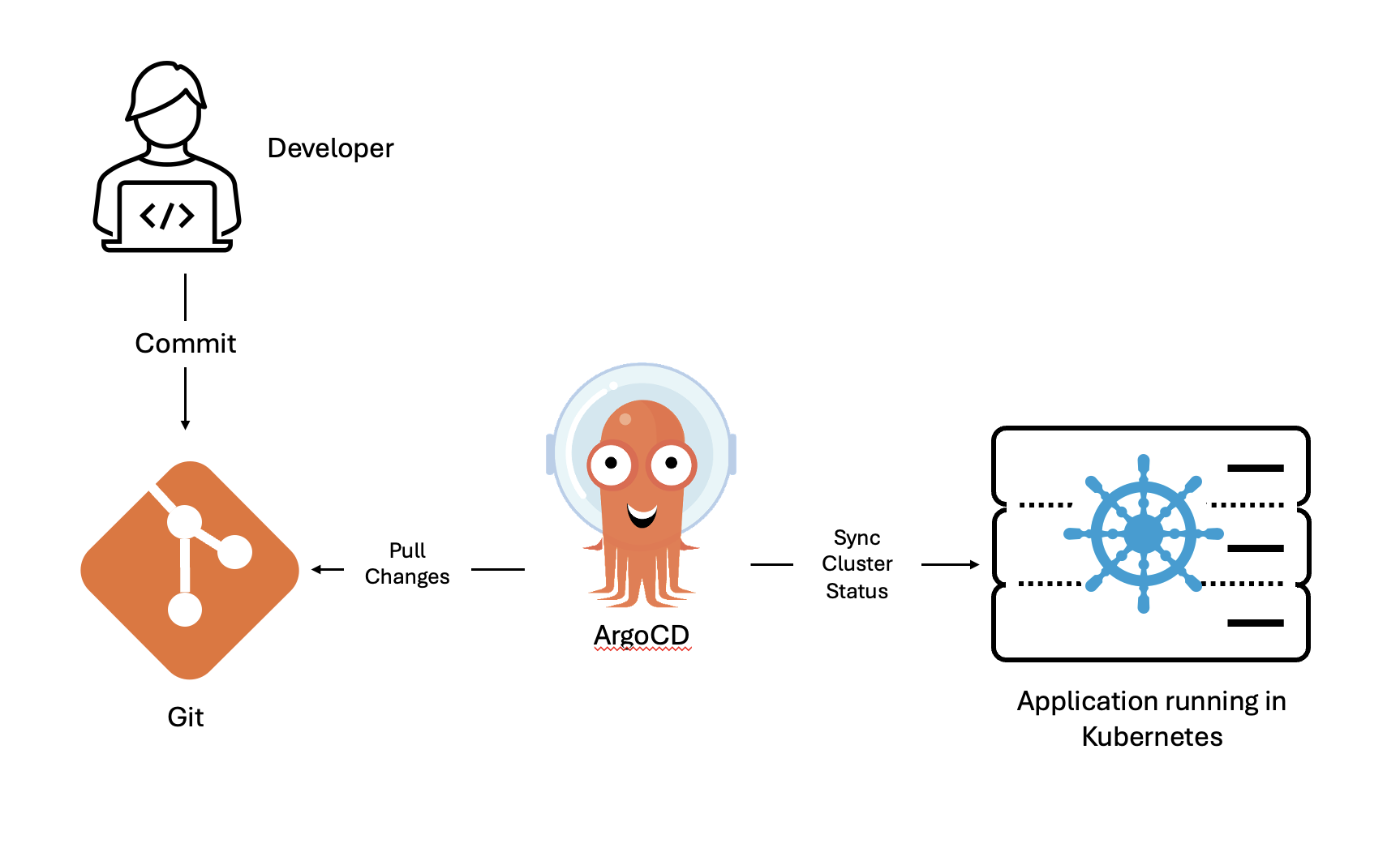
ArgoCD is a declarative, GitOps continuous delivery tool for Kubernetes. It works by ensuring that a Kubernetes cluster’s state matches the configurations that are defined in a Git repository. It facilitates the automatic deployment and synchronization of applications to the desired environments.
We chose to use ArgoCD with Open Liberty because while typical Continuous Deployment (CD) systems adhere to the first two GitOps principles (using declarative configurations and maintaining a versioned, immutable source of truth), they often fall short when trying to implement the latter two principles (ensuring automated delivery and maintaining closed-loop feedback). However, argoCD does help with these two GitOps principles as well.
How does Argo CD help with these two GitOps principles?
-
Automated Delivery: ArgoCD continuously and automatically syncs applications when changes are committed to the Git repository. This ensures deployments are consistent with the repository, bridging the gap between development commits and operational deployments.
-
Closed-Loop Feedback & Control: ArgoCD’s real-time monitoring of application performance ensures that the live state is always aligned with the Git repository’s state. If a discrepancy is detected, ArgoCD offers visual representations of the divergence and provides mechanisms to reconcile those differences, ensuring constant alignment with the intended state.
To take the example application we explored at the start of this post, you’ll see ArgoCD added into our pipeline, ensuring that our cluster remains in sync with what is defined in our Git repository.
How can we get started with ArgoCD and GitOps?
If you’d like to see how you can practically use GitOps principles and ArgoCD to deploy Open Liberty applications, we’ve provided a detailed tutorial that follows on from this introductory post. This step-by-step tutorial walks through how to take an existing Open Liberty application and introduce ArgoCD to help solve configuration drift in your own applications.




